Docker編
コンテナゾンビとの出会い
拙者仮想環境といえばめっちゃ昔のVM WareかVirtualBoxしか使ったことない侍…だったのだが、最近になってローカルLLMとかをいじるためにDockerも使うようになった。でもDockerは正直何やっているかよくワカランという感じで、なーんかコマンド打ってもうまくいかねえな~、みたいなことをやっていると、いつの間にかDocker Desktopのコンテナ一覧がもりもり増殖しまくっておりウワアアアア!!!みたいな事件が起きがちであった。
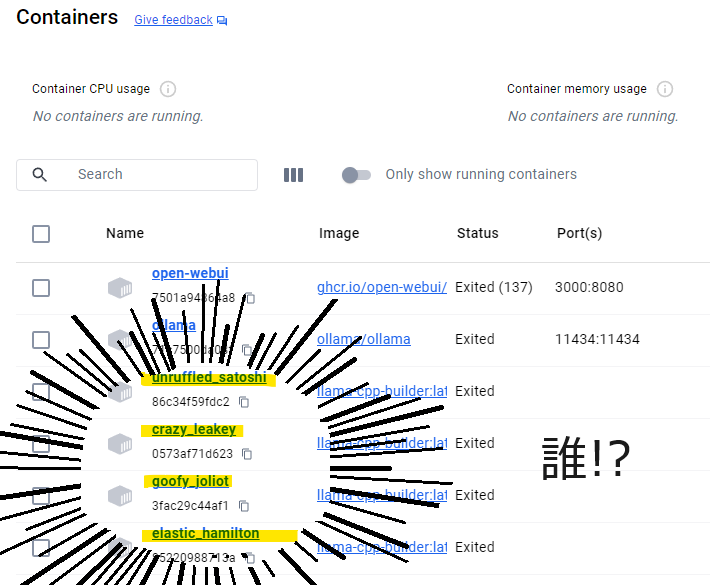
↑この状態が間違っているのはなんとなくわかるのだが(間違ってるよな?)、どう間違っているのかわかっていないので、ちゃんとDockerの概念について理解しようと思いこの記事を書くことにしました。
コンテナとイメージってなにが違うの?
たぶん諸悪の根源はここだ。これを理解できていないのでゾンビっびが大量増殖してしまうことになるのだ。ここから理解を始めよう。
Dockerを使うとき、buildコマンドとrunコマンドがあって、buildするとイメージ一覧になにかしらが追加されて、runするとコンテナ一覧に何かしらが追加されていた。んじゃ、そのイメージとコンテナって結局なんなの? ってことだ。こういうときはChatGPTに聞くのが早い。以前職場の誰かにDockerの説明してもらったとき、タイヤキを使って説明された記憶があったので、タイヤキで解説してもらうことにした。

なるほど…? イメージは型であって実体はなくて、コンテナが実際に動くモノってことなのか。なんとなくゾンビ増殖事件の真実が分かってきた気がするぞ。自分はイメージ作った時点で実体があると思ってて、runするとそいつが動くと思ってたから、特に何も考えずにばんばんrunをやってて、そのたびに新しいコンテナくんが「おぎゃあ」って生まれてたってことなんだろう。怖っ

これでちょっとはDockerと仲良くなれた気がする。やっぱニンゲン大事なのはお互いへの思いやりの心、理解を示す気持ちだよね。じゃあ次はHugging Faceだ。
Hugging Face編
Hugging Faceとの出会い
エックス(旧ツイッター)でAIの情報を眺めていると、Hugging Faceという言葉がとてもよく出てくる。リンク先にはだいたいいつもカワユイ絵文字、☺️+👐みたいなやつがくっついている。

この顔文字を見ていると、新しくてシュッとしていてかっこいいものを見るとウギャアーッっと怖がってしまう自分のような怪異であっても、なんとはなしに親しみを感じさせてくれる。これなら怖くないかも、ということで調べてきた。ふむふむ…自然言語処理・機械学習分野のプラットフォーム…LLMのモデルとかが公開されている場所…おいおい天国かよ…では天国に遊びに行くとしましょう。
せっかくDockerとオトモダチになれたので、Hugging FaceからDocker対応しているLLMモデルを動かしてみるというのをやってみよう。
Hugging Faceアカウントの作成
アカウント作ったほうがよさそうだったのでまずはHugging Faceのアカウントを作る。これはトップページでアカウント作成を促されるので、画面の通りに作ればすぐ終わる。
さてアカウントも作ったのでモデルを選びに行こう。今回は先週話題になった「Qwen/Qwen2-7B-Instruct-GGUF」を試してみることにした。llama.cpp環境での動かし方が書いてあったので、Dockerにllama.cppを入れる→Docker内のllama.cppからモデルを動かす、という順序でやることにする。
Dockerでllama.cpp環境をつくる
基本的にはHugging Faceのドキュメントを見ながら進める。Dockerは結構下のほうに記載がある。(Egdeの翻訳だとDockerが港湾労働者になるのだが…??)
まずはイメージを作るところから。タイヤキの型の部分だ。イメージに詰め込みたいのはこんな感じ。
- OSは最新のUbuntuにする
- 作業フォルダを作る
- llama.cppのソースコードをgitから取ってくる
- UbuntuにCUDAのToolkitをインストールする
- Ubuntuにそのほか必要そうなライブラリをインストールする
- llama.cppをCUDAオプションを有効化した状態でビルドする
これをDockerfileに記述すれば、buildコマンドを実行したときに記載内容を反映したイメージを作ってくれるみたいだ。このあたりはChatGPTに聞いたりしながらDockerfileを書いてもらった。
ChatGPTにへこへこしながら書いたDockerfileがこれ。↓
FROM ubuntu:latest
ENV DEBIAN_FRONTEND=noninteractive
RUN apt-get update && apt-get install -y \
build-essential \
git \
cmake
WORKDIR /app
RUN git clone https://github.com/ggerganov/llama.cpp.git
WORKDIR /app/llama.cpp
RUN apt install -y nvidia-cuda-toolkit
RUN make LLAMA_CUDA=1 all
CMD ["/bin/bash"]
適当な作業フォルダを作ってDockerfileを配置する。
cd [作った作業フォルダ]
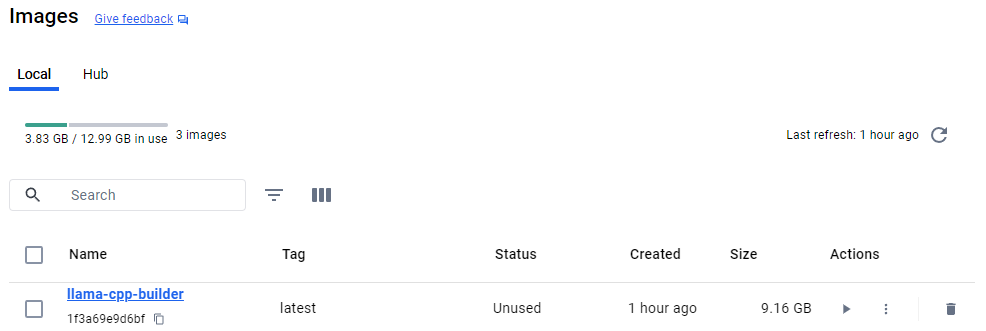
docker build -t llama-cpp-builder .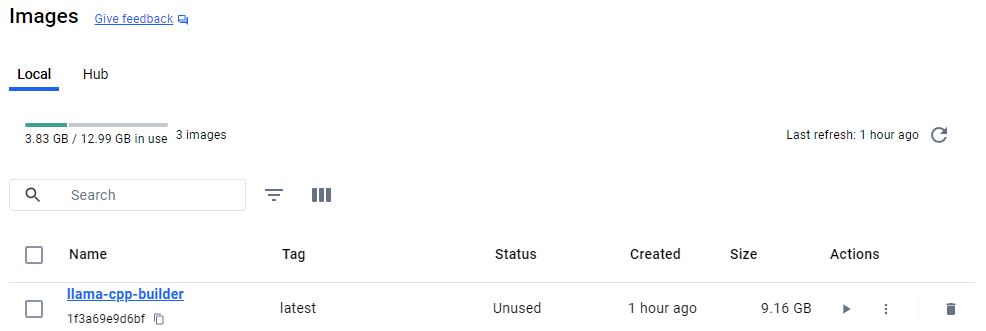
これで型は完成。Dockerfileは一発で思い通りになることはなかなかないので、実際はbuildのときにキャッシュを使ってbuildコマンドを何度も実行した。↓こんな感じ
docker build --cache-from=llama-cpp-builder -t llama-cpp-builder .イメージがうまくできたらコンテナを動かす。タイヤキタイムだ。llama-cpp-builderからllama-cpp-containerを作る。ジュワ~
docker run -it --rm --name llama-cpp-container llama-cpp-builderコマンドが成功するとコンテナ一覧に新しいコンテナが増えて、コマンドラインのほうもシェル実行の見た目に変わる。

いちおうllコマンドでllama.cppのバイナリがあるか確認する。なんか今週ちょうど更新が入ってバイナリ名が変わったらしい(main→llama-cli)。最初mainがない!ってめっちゃ焦った。
Qwen/Qwen2-7B-Instruct-GGUFを動かす
Hugging FaceのQwen2ページからモデルをダウンロードする。14GB。わお。DLしたデータをコンテナの中にコピーする。ほんとはコマンドでできそうだけど、今回はDocker Desktopからコピーすることにした。稼働中のコンテナのページ>Filesから、modelsフォルダにドラッグ&ドロップでコピー。毎回このモデルを使う場合はイメージにDLコマンド入れる感じになるが、今回は1回だけのお試しなのでコンテナ起動時に直接コピーしている(こういうことが言えるようになるので、Dockerと仲良くなっておいてよかったなあ!)。
コピーが完了したらllama-cliを使って推論を実行する。llama.cppのサンプルコードをそのまま使う。「Building a website can be done in 10 simple steps:\nStep 1:」ということで、Webサイトの作り方を教えてもらう感じの質問だ。コマンドは、モデル名のところだけQwen2に差し替える。
./llama-cli -m models/qwen2-7b-instruct-fp16.gguf -p "Building a website can be done in 10 simple steps:\nStep 1:" -n 400 -e実行するとCUDAのメモリ足りないエラーが出たが、回答は返ってきた。GPUがしょぼすぎて動かなかったか…。CPUだけで動いたためか、生成はちょう遅かった。でもちゃんと動いた。

おわりに
こうやっていろいろ動かしてみたあとだと、Ollamaのらくちんさが際立ちますね。世の中の便利系ライブラリを作ってUpしてくれる人たちに頭が上がらない。。。