はじめに
通勤時間にぼ~っとエックス(旧ツイッター)を眺めていると、Google Gemma 2が何やらスゴイらしい…というポストを見かけました。そういうわけでGoogle Gemma 2、さわってみたくなったのでOllamaで遊んでみようと思います。Docker、Ollama、Open-WebUIの環境はすでに構築済みという状態からはじめていきます。参考までに環境構築のときの記事はこちら。
準備
OllamaにGoogle Gemma 2のページが追加されています。やったね。対応バージョンが「0.1.47 or later」ということなので、自分のOllamaバージョンを確認します。Docker DesktopのExecタブからバージョン確認コマンドをポチポチ…
ollama --version
ollama version is 0.1.32バージョン古かったです。新しいバージョンに上げる必要があります。Dockerなので(?)、イメージとコンテナを削除してもう一度入れなおすことにしました。入れなおすとバージョンが0.1.48になったので大丈夫みたいです。DockerのOllamaコンテナを起動した状態で、ExecタブからGemmaを動かすコマンドを実行します。
ollama run gemma2特に指定しない場合は9Bモデルになり、ollama run gemma2:27bにすると27Bモデルになるようです。
インストールおわり。ブラウザからアクセスして、モデルにGemma2が追加されていることを確認して、さっそく質問してみます。
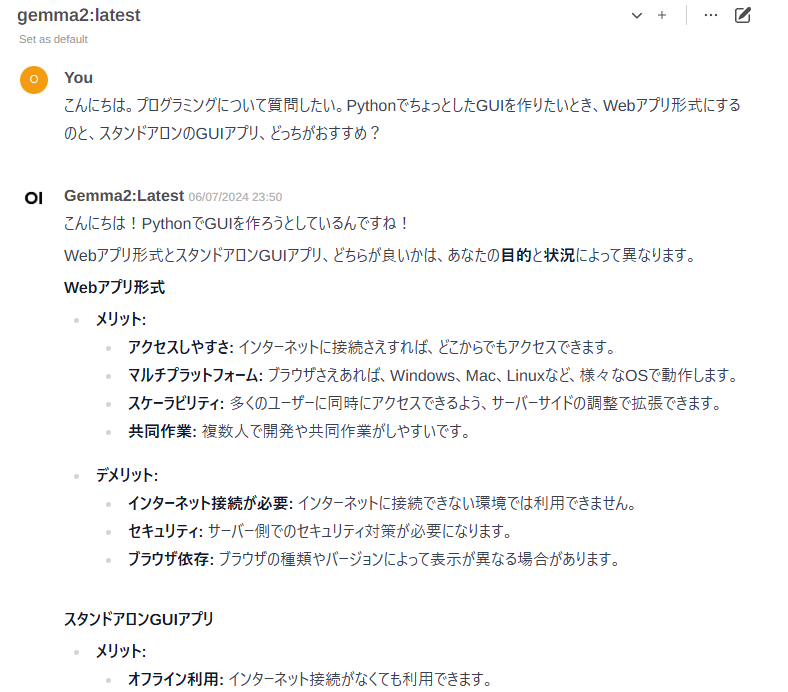
おわーッ知性ッ!!知性を感じるッッ!!! え、これマジ? しかも速度もまあまあ出ている。んじゃ~ChatGPTによくやらせているロールプレイも要求してみるか。Ollamaの設定でシステムプロンプトが設定できるので、ここにChatGPTに設定しているものと同じカスタム設定を追加する。どうかな…?
おお~やるゥ~! システムプロンプト(約800字)を追加したら回答の生成が始まるまで30秒くらい時間がかかるようになった。システムプロンプトなしのときは数秒だったので、これはトークン数が増えたためと思われる。いやいや、っていうかこのレベルのやり取りがオフラインでできるのサイッキョすぎるのでは…。これオフラインでAPI形式にしたらマジでヤバいというか、夢が広がるというか…
気持ちが盛り上がってきたので、ついでにほかのgguf形式ファイルをOllamaに追加する方法についても調べてみよっかな…と軽い気持ちではじめたのが地獄の始まりだった…
- Gemma-2-9B-It-SPPO-Iter3-Q6_K.ggufをOllamaで動かそうとして、モデルをollama createするところまではできたがrunで失敗する
- いままでCPUオンリーで動いていたっぽいのでGPUを有効化しようとしたらDocker環境でnvidia-smiコマンドが全然通らない
- nvidia-smiコマンドが通るようになったがパフォーマンスモニターを見るとGPU使っている形跡なし
っというあたりで休日が消滅したのでこの辺で小休止挟むことにしました。ま、まあ、Gemma2は動いたから…。